Emotion-Aware Recommendations: Building a YouTube Recommender That Understands Feelings
Ever wondered what AI fans really want to watch next?
I turned 180K+ YouTube comments into personalized video suggestions using sentiment analysis + clustering.
In an era where algorithms suggest what we watch, listen to, and read, I wanted to ask a deeper question: What if we could recommend content not just based on what it's about — but on how it makes people feel?
This idea led me to build the Sentiment-Driven Video Recommendation System, a fully deployed machine learning pipeline that recommends YouTube videos using not only content similarity but viewer emotions extracted from comments and unsupervised video clustering.
Let me walk you through how I engineered it — and what I learned along the way.
Live App
The Problem
Most recommender systems ignore emotions. What if someone liked a video but felt confused or disappointed? I built a system that captures emotional impact using NLP.
The Approach
The system computes a final score for each candidate video using the following formula:
Final Score = Content Similarity × Sentiment Score × Cluster Boost
- Content Similarity (TF-IDF + Cosine Similarity)
To capture semantic similarity between videos, I transformed transcripts into high‑dimensional numeric vectors using TF‑IDF (Term Frequency–Inverse Document Frequency).
Key steps:
- Text cleaning: lowercase, stopwords, punctuation
- Vectorization (TfidfVectorizer): ngram_range=(1,2) → unigrams and bigrams; max_features → dimensionality control
- Result: TF‑IDF matrix ∈ ℝⁿˣᵐ where n = videos and m = unique terms
- Cosine similarity: Symmetric matrix; each cell (i, j) reflects topical similarity
- Content baseline: Serves as the base of the content‑driven recommender, independent of user behavior
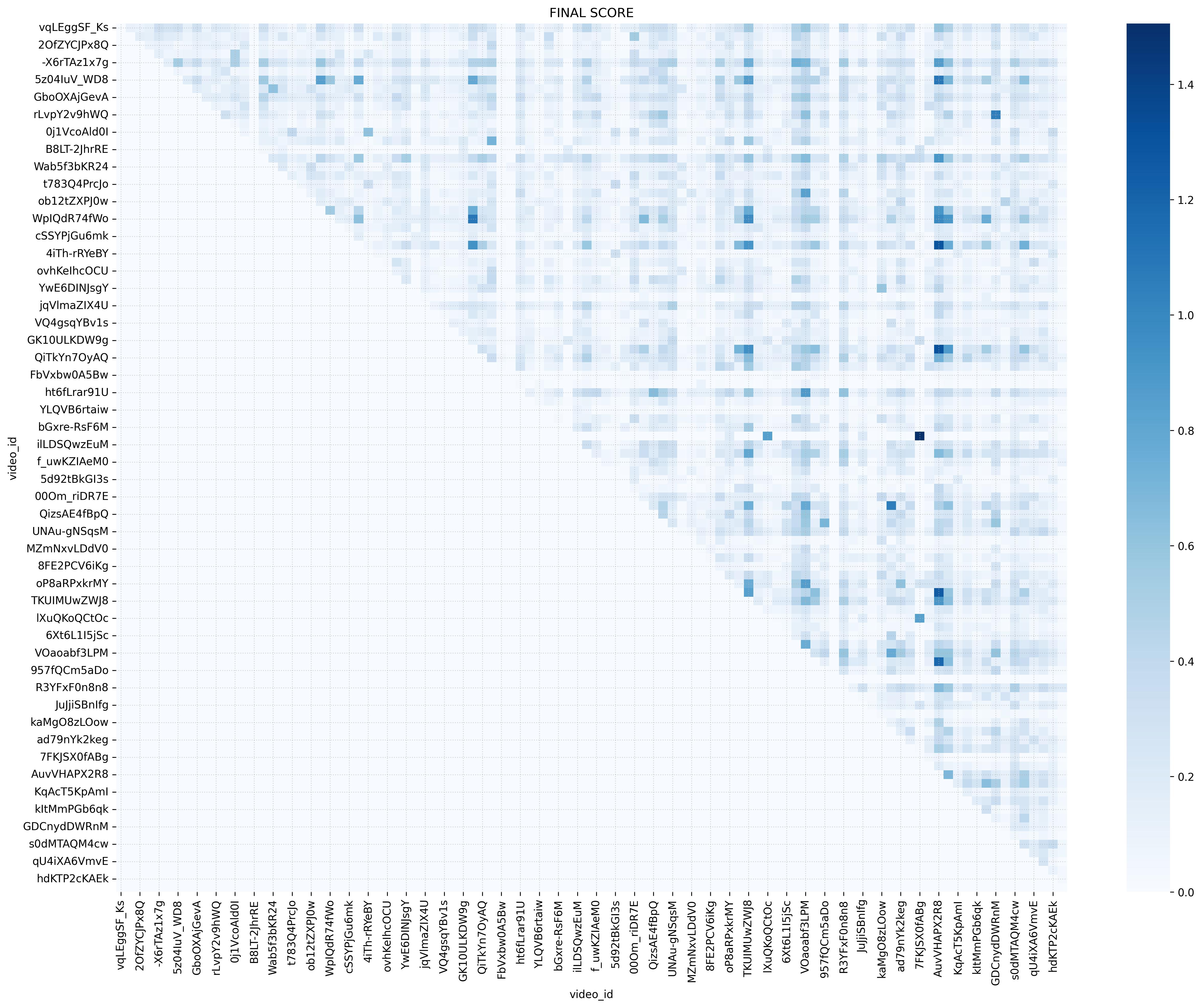
Cosine similarity matrix (TF‑IDF) - Sentiment Analysis (RoBERTa + PySpark)
To incorporate audience perception, I used a RoBERTa model fine‑tuned on GoEmotions to run multi‑class sentiment analysis.
Technical pipeline:
- Parallelization: per‑video comments processed in parallel with PySpark
- Inference: each comment yields a distribution over 29 emotions (softmax)
- Aggregation: per‑video mean → a unique emotion vector per content
Sentiment Score calculation:
Sentiment Scorei = 1 + Σj wj · pij- pij: probability of emotion j for video i
- wj: weight for each positively associated emotion
- Effect: multiplier over semantic similarity; favors positive reactions

Wordcloud of positive comments (sentiment features) - Clustering (K-means + DBSCAN)
To avoid redundant recommendations and ensure topical diversity, I applied unsupervised clustering on combined content, emotion, and engagement features.
Features used:
- Emotion vector: 29D (mean of per‑emotion probabilities)
- Engagement: view count (log), like ratio, duration
- Category: one‑hot/category embeddings
Techniques applied:
- K‑means: normalization with StandardScaler; k via elbow method + Silhouette Score
- DBSCAN: detects dense clusters and outlier/viral content
- Cluster Boost: ×1.2 if candidate and seed share a cluster → balances relevance and variety
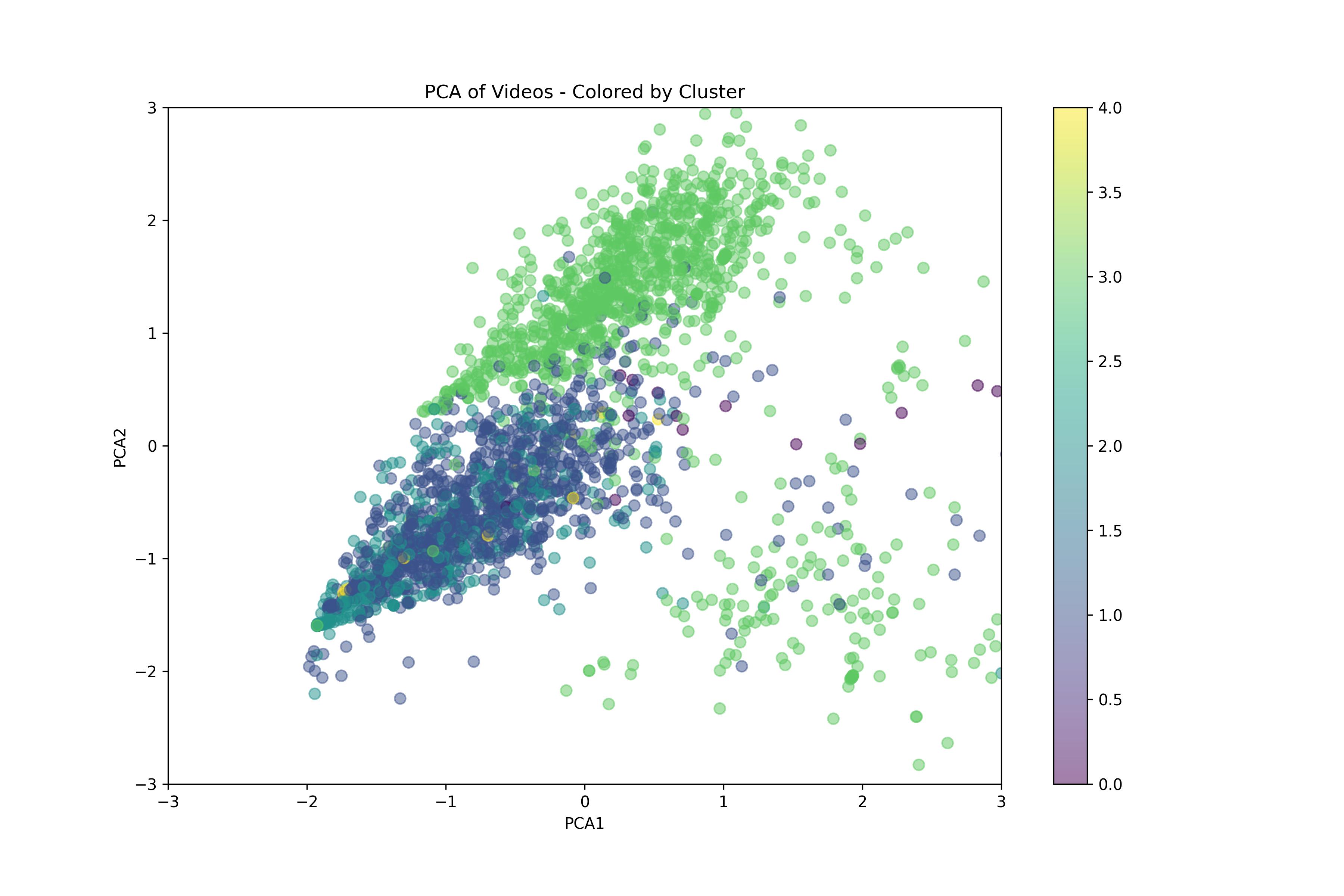
Video clusters (K‑means)
Tech Stack
Natural Language Processing (NLP)
- RoBERTa + GoEmotions: Fine‑tuned model (29 emotion categories)
- Text cleaning: NLTK: tokenization, stopwords, normalization
- Outcome: Emotion vector per video from hundreds of comments
Data Ingestion & Enrichment
- Data sources: YouTube Data API: transcripts, metadata, comments
- Dataset: Textual content, emotional signals, engagement metrics
Scale-out Processing
- Distributed processing: 180,000+ comments with PySpark
- Aggregations: Per‑video summaries for efficient queries
Production Deployment
- Service: FastAPI REST API packaged with Docker
- Deployment: Runs on Google Cloud Run (auto‑scaling, low latency)
Key Results
- Interactive web app: Explore personalized recommendations by emotion and content
- Production API: Serves recommendations with low latency
- Emotion visualization: Each video shows an emotion map explaining the suggestion